


Qualité de la donnée, nouvelle frontière de l’IA
L’IA générative connaît une adoption massive, mais les gains de performance des grands modèles ralentissent. Le modèle « plus de données = meilleures performances » atteint ses limites, notamment faute de données réellement qualitatives. Dans ce contexte, la qualité des données devient un avantage stratégique majeur. Cet article explore comment l’IA peut apprendre à sélectionner intelligemment ses propres données d’entraînement, à travers l’exemple de DataRater de DeepMind.
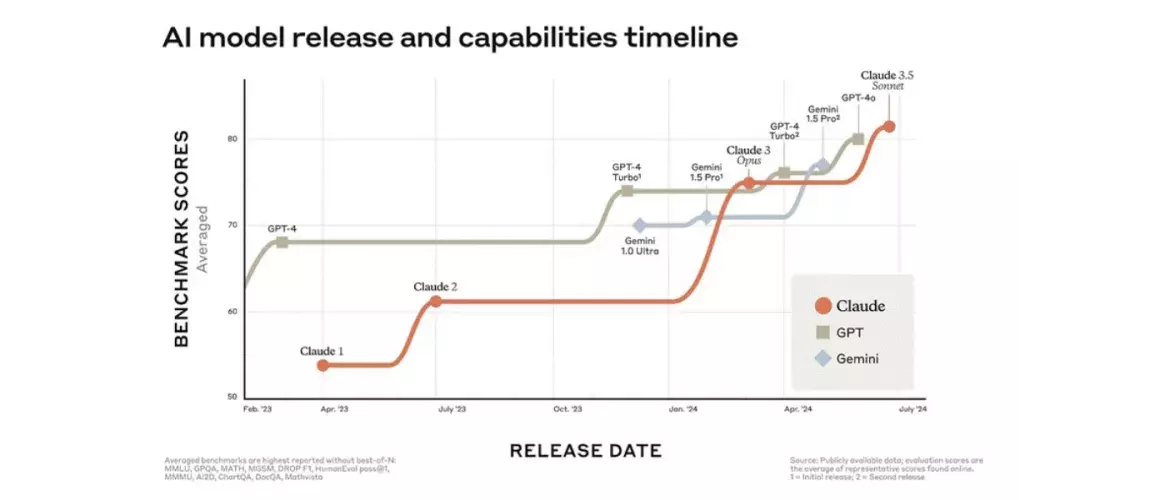
I. Le mythe de la donnée infinie s’effondre
Pour bien appréhender les contraintes actuelles des LLM, il est crucial de comprendre comment sont formés les modèles les plus sophistiqués.
Les grands modèles de langage s’entraînent d’abord sur de vastes données pour apprendre les bases du langage, puis sont ajustés via le RLHF pour mieux correspondre aux attentes humaines. Jusqu’à récemment, augmenter la taille des modèles et des corpus permettait des progrès spectaculaires, comme le montrent GPT-3 ou LLaMA. Aujourd’hui, cette stratégie atteint ses limites : les nouveaux modèles n’apportent plus de gains exponentiels, soulignant que la qualité des données prime désormais sur la quantité.
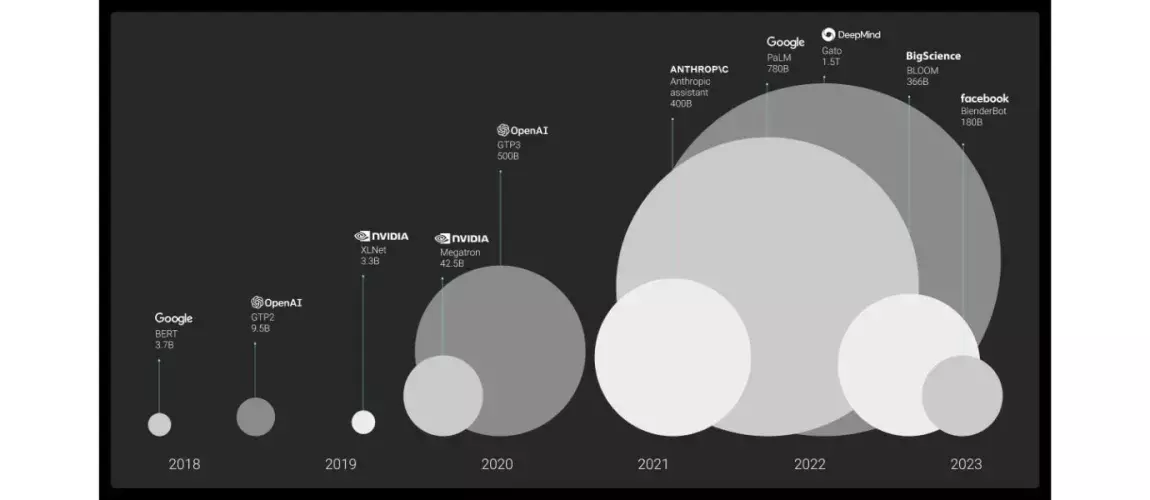
II. DataRater : une réponse innovante à un problème fondamental
Pour relever le défi de la qualité des données, DeepMind a développé DataRater, une IA capable de choisir automatiquement les données les plus pertinentes pour l’entraînement des modèles. Contrairement aux méthodes classiques basées sur des règles ou des heuristiques, DataRater évalue en continu l’impact de chaque donnée sur la performance du modèle grâce à trois mécanismes principaux : le meta-learning, qui anticipe la valeur de chaque donnée ; l’optimisation par gradient, qui affine cette évaluation sur plusieurs étapes d’entraînement ; et le filtrage par batch, qui privilégie les exemples de grande valeur tout en éliminant le contenu bruité ou non pertinent.
Les tests sur différents modèles et corpus montrent des résultats impressionnants : près de 46 % d’économie de calcul, une bonne généralisation à des modèles de tailles variées, et une détection automatique des données de faible qualité (erreurs OCR, textes incohérents, langues non désirées).
En pratique, DataRater rend la curation des données plus efficace, scalable et flexible, permettant d’optimiser l’entraînement pour des objectifs précis sans intervention humaine et en réduisant le temps et les ressources nécessaires.
III. Pourquoi c’est une rupture stratégique
L'amélioration de la sélection des données constitue un véritable tournant dans l'approche de l'entraînement des modèles. L'accomplissement de diminuer presque 70 % la taille d'un ensemble de données tout en préservant jusqu'à 95 % de l'efficacité représente un bouleversement de paradigme : la valeur ne se trouve plus dans le volume massif des données, mais plutôt dans leur pertinence et leur variété. Cette méthode permet une diminution considérable des coûts de formation, tant sur le plan financier réduction des ressources de calcul et du temps de traitement que environnemental, grâce à une empreinte énergétique considérablement réduite.
Outre l'amélioration technique, cette avancée redéfinit le pouvoir stratégique dans le secteur de l'IA. L'atout concurrentiel n'est plus uniquement basé sur la possibilité d'entraîner les modèles les plus grands sur les corpus les plus étendus, mais sur la faculté de choisir et d'optimiser les meilleures données. La gestion des données devient donc un facteur d'innovation et de distinction plus pérenne que la simple quête de l'ampleur des modèles.
IV. Et pour les entreprises ?
Pour les entreprises, il est plus efficace de valoriser leurs propres données plutôt que de chercher de grands volumes externes. En triant, étiquetant et organisant leurs informations internes (clients, documents, dialogues, données RH ou juridiques), elles peuvent créer des modèles spécialisés et performants. Cette approche est aussi responsable et durable, réduisant l’impact énergétique et les risques liés aux biais ou à la confidentialité, tout en passant d’une IA basée sur la quantité à une IA ciblée et contrôlée.
Conclusion :
L'avenir de l'intelligence artificielle ne dépend plus seulement de la capacité de traitement ou de la taille des modèles.
Cela fait appel à notre compétence pour déceler de l'or dans les énormes quantités d'informations, à apprendre de manière plus judicieuse plutôt qu'en masse.
Dans un contexte où l'accès à des données premium se raréfie, la capacité à les choisir constitue un atout stratégique majeur.
Le sujet vous intéresse ? Nos experts vous répondent

Avec la création d’un pôle spécialisé en Data/IA, mc2i se positionne comme un partenaire de confiance en Data Transfo au service de la démocratisation de la donnée et d’un usage responsable.


