


Le Data Mesh remplacera-t-il nos Data warehouses ?

Le Data Mesh est un concept innovant qui propose une nouvelle modélisation technique, méthodologique et organisationnelle.
Qu’est-ce que le « Data Mesh » ?
Ce concept est basé sur une gestion décentralisée de la donnée. Les données sont gérées indépendamment dans des “Domaines de données”.
- Chaque domaine administre ses propres pipelines de données : « Les Data Mesh fédèrent la propriété des données entre les propriétaires de données des domaines ».
- Ainsi, le rôle du Data Mesh est de faciliter la communication entre les données.
- Les domaines sont autonomes et doivent impérativement gérer leurs propres données de leur côté au sein de leurs pipelines ETL.
- Des règles de gestion propre à tous les domaines permettent de stocker, cataloguer et maintenir des contrôles d’accès pour ces données brutes.
- Enfin, de ces transformations en découle l’exploitation des données en fonction des besoins utilisateurs (analytiques et/ou opérationnels)
Un paradigme : le modèle décentralisé
Avant de parler du Data Mesh, il est nécessaire de réexpliquer l’architecture d’un pipeline data classique avec la combinaison d’un Data Lake et de Data Warehouses. Un Data Lake permet de centraliser le stockage de toutes les données brutes de l’entreprise mais généralement les données n’y sont ni traitées ni fiabilisées et sont dans des formats divers (structurées, non structurées, semi structurées). Puis, les différents domaines fonctionnels de l’entreprise puisent dans le Data Lake pour alimenter leur traitement de chargement des données dans leurs Data Warehouse.
Un Data Warehouse est un système complet qui intègre les données préparées, des moteurs d’exécutions et d’autres outils divers de traitements analytiques. Il interagit avec les applications, les scripts et les Business Analysts.
Dans ce modèle très structuré et séquentiel, nous avons donc une double séparation :
- Séparation logique entre les données brutes du Data Lake et les données opérationnelles des Data Warehouses.
- Séparation fonctionnelle via la segmentation des Data Warehouses généralement opérée selon les unités opérationnelles.
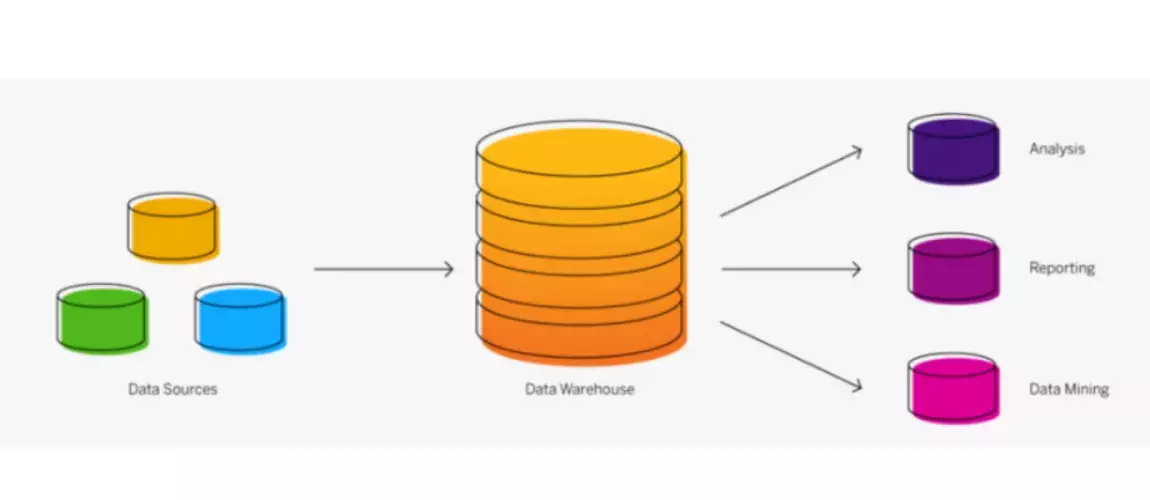
Attention, il y a des désavantages à ce mode de gestion de données :
- On peut parler du stockage logique des données. Comme vu précédemment, le Data Warehouse intervient lorsque nous nous trouvons dans le cas d’une grosse quantité de données et le problème ne se trouve pas au niveau du stockage de la donnée mais au niveau de la logique de compartimentage. Le Data Warehouse a pour objectif d’évoluer dans le temps, ce qui inclut inévitablement de nouveaux cas d’usage et de besoin et c’est là que la limite de cette méthode apparaît.
- Il y a aussi, les règles de gestion de la donnée qui sont à respecter qui ne sont pas équivalentes à tous les services.
C’est le Data Mesh qui peut répondre à ces deux derniers points avec son mode très particulier de décentralisation de la donnée.
Le Data Mesh est un paradigme puisqu'il repose sur la décentralisation. Normalement, lorsque nous récupérons une grande quantité de données, nous souhaitons obtenir une centralisation de cette dernière mais le Data Mesh prend le problème à l’envers.
En effet, on peut prendre pour image le fonctionnement d’une entreprise : découpé en départements avec leurs problématiques bien spécifiques en fonction de leurs sujets et leur contexte qui leur est propre.
Ci-dessous la représentation schématique d’un fonctionnement d’un Data Warehouse :
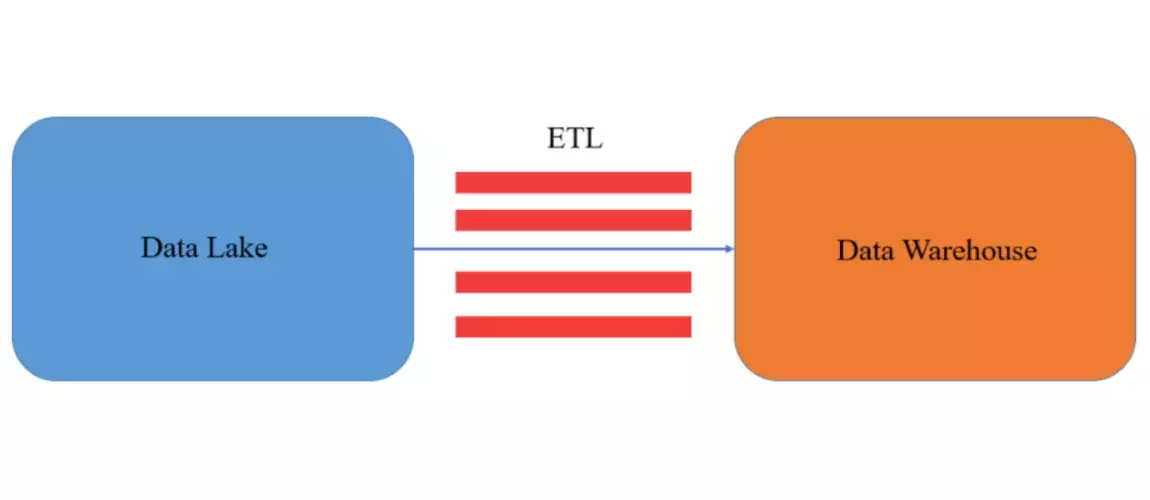
La représentation se fait de manière linéaire lorsque l’on se trouve dans un Data Warehouse. Le Data Lake contient les données brutes qui n’ont subi aucune transformation. C’est l’étape suivante : le passage dans les pipelines (ETL) qui filtrent les données et les transforment. Enfin, le Data Warehouse stocke les données agrégées.
Ainsi, comme évoqué précédemment, le Data Mesh fonctionne non pas de manière linéaire mais par domaine :
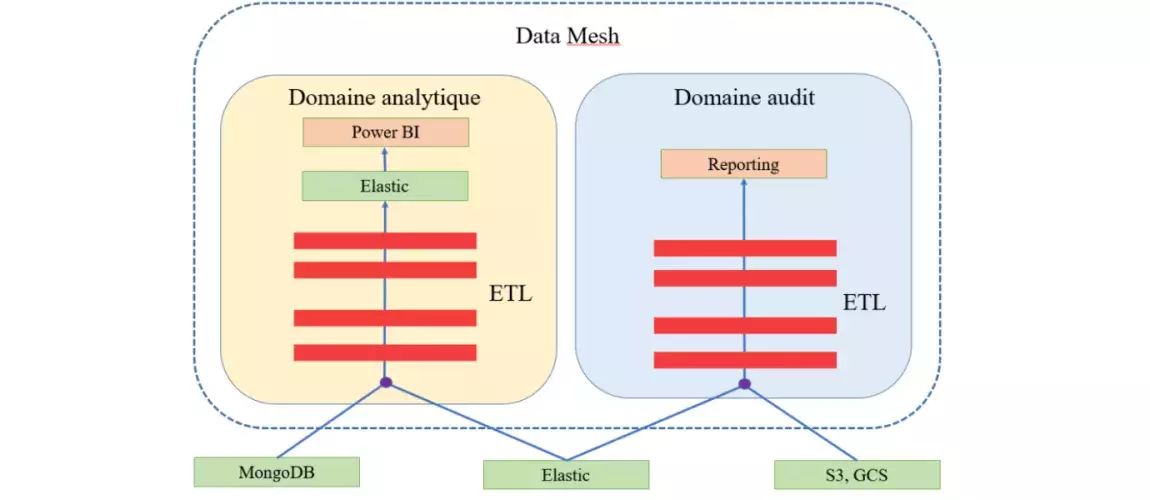
On remarque qu’une même base de données peut être utilisée pour alimenter plusieurs domaines (dans le schéma ci-dessus, la base Elastic alimente aussi bien les domaines analytique et audit).. Dans le cas du domaine analytique, on remarque que les ETL qui déversent de la donnée dans la base de données SQL ont leurs règles de gestion qui leurs sont propres.
L’outil POWER BI de Business Intelligence (BI) peut ainsi requêter des données qui ont été préparées spécialement pour l’analyse dans le but de créer des tableaux de bords dynamiques permettant la prise de décision.

Dans le cas du domaine audit, bien que la donnée provenant de la base Elastic soit la même, les ETL peuvent transformer la donnée différemment du premier domaine. Cela permettra d’obtenir les reportings voulus sans avoir à remettre en question l’architecture en amont du pipeline. En effet, mettre en place des ETL spécifiques à un domaine n’altère pas le travail réalisé dans un autre domaine.
Tous les outils et par conséquent les données qui en découlent sont adaptés en fonction du besoin du domaine spécifique : les données ne sont plus regroupées dans un seul et unique endroit, mais il existe maintenant un accès aux bases de données brutes et fichiers plats. Permettant une adaptation de la mise en forme des données en fonction du domaine.
Data Mesh / Data Warehouse: deux modèles qui s’opposent
En résumé, voici les différences concrètes entre le Data Mesh et le Data Warehouse :
- Il n’y a plus de puits où se retrouvent toutes les données transformées d’une seule et unique manière mais bien plusieurs bases adaptées au besoin du domaine.
- Les ETL sont multipliés puisque l’on peut en trouver dans chaque domaine. Le bénéfice de cette méthode est d’avoir une vision totale et les droits de modification du processus de transformation de la donnée.
C’est un réel changement dans la façon de traiter la donnée : ce nouveau mode a un impact direct sur l'organisation et permet de remettre en question le paradigme classique du Data Warehouse.
Mais il faut bien avoir en tête que nous avons ici non pas la solution à tous les problèmes au sein des grandes entreprises, mais une nouvelle alternative à la centralisation de la donnée.
Le sujet vous intéresse ? Nos experts vous répondent

Avec la création d’un pôle spécialisé en Data/IA, mc2i se positionne comme un partenaire de confiance en Data Transfo au service de la démocratisation de la donnée et d’un usage responsable.



