


Apache Spark : moteur clé des stratégies data-driven

Dans un contexte où la donnée devient stratégique, les entreprises misent sur le data-driven pour prendre des décisions éclairées et anticiper l’avenir grâce à la Data Science et à l’IA. Mais exploiter ces volumes massifs exige des données fiables et un traitement rapide à grande échelle. Comment analyser efficacement ces données toujours plus nombreuses sans sacrifier la vitesse et la fiabilité ? Des technologies comme Apache Spark, capables de paralléliser les traitements, offrent une réponse clé à ce défi.
La stratégie data-driven et ses défis technologiques
Le terme data-driven est aujourd’hui omniprésent dans le monde de l’entreprise. On peut le traduire littéralement par axé sur la donnée ou piloté par la donnée. Ce terme désigne une approche où l’analyse des données joue un rôle central dans la prise de décision. Concrètement, une stratégie data-driven repose sur l’exploitation des données internes et du marché afin d’orienter les choix stratégiques. Plutôt que de s’appuyer sur l’intuition ou des processus hérités, elle permet de prendre des décisions éclairées, au bon moment, en se basant sur des informations factuelles et actualisées.
Adopter une telle approche offre de nombreux avantages :
- Optimisation des performances grâce à une prise de décision plus efficace
- Anticipation des évolutions du marché pour s’adapter rapidement aux tendances
- Renforcement de la compétitivité en prenant une longueur d’avance sur la concurrence
- Réduction des risques grâce à des analyses précises et objectives
L’essor du Big Data rend cette transition vers le data-driven plus pertinente que jamais. Les entreprises doivent s’adapter pour ne pas se laisser distancer par leurs concurrents. En parallèle, la démocratisation des outils d’analyse de données facilite cette transformation, la rendant accessible à toutes les organisations, quel que soit leur niveau de maturité digitale.
L’implémentation d’une stratégie data-driven implique une transformation technologique et culturelle de l’entreprise. Il ne s’agit pas seulement d’adopter des outils d’analyse, mais de repenser la prise de décision à tous les niveaux d’une entreprise. La première étape consiste à structurer le cycle de vie des données : collecte, stockage, traitement et analyse. Ces données, issues de sources variées telles que les capteurs IoT, le CRM, les logs web, les réseaux sociaux et les API, doivent être centralisées dans une infrastructure adaptée, qu'il s'agisse d'un Data Warehouse, d'un Data Lake ou d'un modèle hybride (Data Lakehouse). Pour traiter de gros volumes, des solutions comme Hadoop ou Spark sont privilégiées.
Cependant, une approche data-driven ne repose pas uniquement sur la technologie. Il est essentiel de démocratiser l’accès aux données tout en optimisant les ressources IT. Dans un contexte où les compétences informatiques sont rares et coûteuses, les outils sans code permettent aux développeurs citoyens, des collaborateurs non développeurs mais à l'aise avec les outils numériques, de créer rapidement des applications ou des automatisations pour répondre à leurs besoins métiers, sans mobiliser d'équipes techniques. Grâce à des solutions drag-and-drop comme Alteryx ou Dataiku, ils peuvent exploiter les données en autonomie, avec l'accompagnement ponctuel de data engineers pour structurer et optimiser les flux, afin de favoriser l'autonomie et l'adoption du data-driven à l'échelle de l'organisation.
Dans cette logique d’autonomisation, le Data Mesh apporte une approche plus décentralisée. Plutôt que de centraliser toutes les données dans un unique Data Lake, il repose sur une gouvernance distribuée où chaque équipe métier est responsable de ses propres données, tout en respectant des standards communs. Ce modèle favorise l’agilité et s’adapte mieux aux grandes organisations aux besoins multiples et évolutifs. Ainsi, une stratégie data-driven réussie repose sur un équilibre entre une infrastructure robuste et une évolution des pratiques, faisant de la donnée un véritable moteur de performance et de compétitivité.
Spark et le calcul distribué : Un levier technologique pour les entreprises
Spark est un mot qui est devenu à la mode depuis quelques années, mais en quoi consiste cette technologie ?
Apache Spark est un framework open-source conçu pour faire du traitement distribué de données à grande échelle. Il a été créé en 2009 à l’Université de Berkley pour répondre aux limites d’Hadoop MapReduce*. En effet, Spark utilise principalement la mémoire RAM pour traiter les données, ce qui le rend plus efficace et rapide que MapReduce qui utilise principalement le disque dur
*MapReduce est une méthode pour traiter de grandes quantités de données en deux étapes : d’abord on transforme les données en paires clé-valeur (Map), puis on regroupe les éléments ayant la même clé pour appliquer un traitement dessus, comme un comptage ou une somme (Reduce).
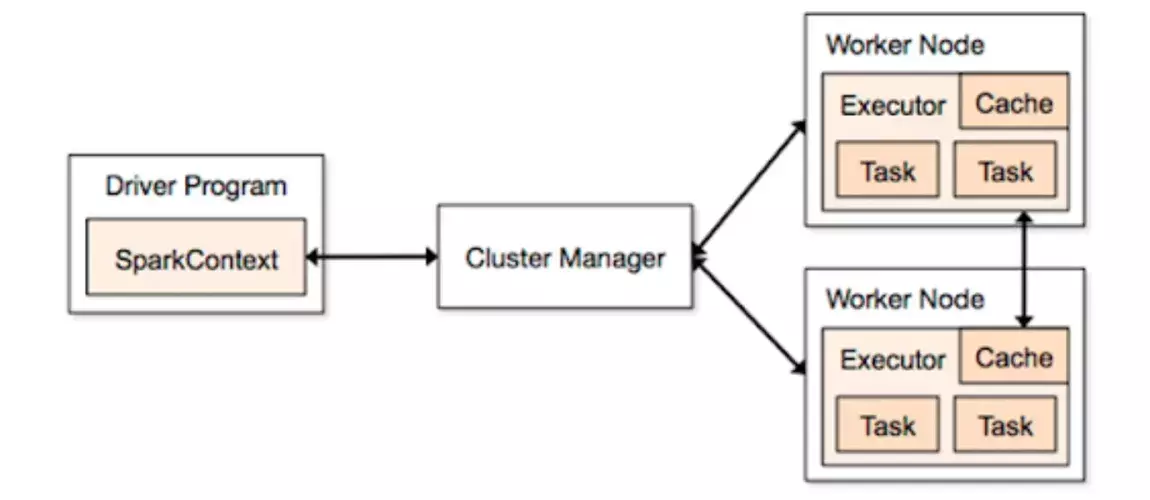
Spark se base sur un modèle maître-esclave où un Driver coordonne l'exécution de tâches sur plusieurs Executors. Ces Executors sont déployés sur un cluster de machines dont la gestion des ressources est assurée par un Cluster Manager qui est chargé d’allouer dynamiquement les ressources nécessaires aux Executors pour optimiser le traitement.
Vous n’avez rien compris ? Reprenons étape par étape ! Concrètement, lorsqu’un traitement est soumis à Spark, le driver décompose les données et le traitement en plusieurs petits fragments appelés partitions pour les données et stages pour les traitements. Chaque stage est ensuite décomposé en plusieurs tasks indépendants, qui sont répartis sur les différents nœuds du cluster pour être exécutés en parallèle. Chaque nœud réalise les calculs sur les partitions de données grâce au modèle de calcul in-memory (puisque la taille des partitions est inférieure à la taille du nœud), ce qui permet d’éviter des écritures coûteuses sur disque et d'accélérer les traitements.
Chaque executor communique ensuite les résultats au driver, qui agrège les différentes sorties des tasks pour produire le résultat final du traitement. Si jamais une tâche échoue, Spark détecte l'échec et réexécute automatiquement la tâche concernée sur un autre nœud du cluster, garantissant ainsi la tolérance aux pannes et la résilience du traitement.
Maintenant qu’on a compris le fonctionnement d’Apache Spark, on comprend assez facilement ses avantages :
Le premier atout majeur, réside dans la performance. En effet le moteur de calcul en mémoire permet de traiter les données plus rapidement que les solutions qui se basent sur le calcul sur disque. De plus, grâce à son architecture distribuée, il exploite pleinement l'exécution en parallèle des tâches sur plusieurs nœuds garantissant une scalabilité efficace face aux gros volumes de données.
Le deuxième atout majeur de Spark est sa résilience face aux pannes. Les objets sparks sont conçus pour être tolérants aux pannes : en cas de perte de données ou de nœud, Spark peut facilement recalculer les données manquantes à partir de leurs sources originales assurant ainsi une continuité du traitement. Cette tolérance est rendue possible également grâce au cluster Manager qui surveille l’état des nœuds et réalloue les tâches en temps réel garantissant une exécution sans interruption.
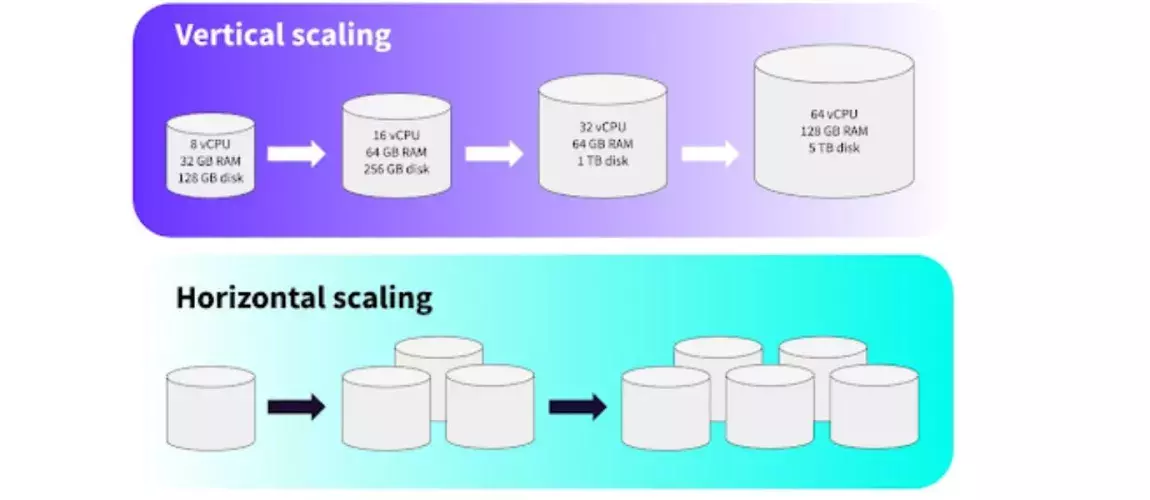
Enfin, le troisième point fort de Spark est la gestion intelligente des ressources. Son modèle de scalabilité horizontale (Horizontal scaling) permet d’adapter la puissance de traitement en fonction des besoins. Ce qui évite la surconsommation inutile. Son intégration avec des outils d’orchestration (Yarn par exemple) permet de faire de l’auto-scaling efficace ajustant dynamiquement les ressources pour ne consommer que ce qui est nécessaire.
Comment le calcul distribué peut contribuer à la stratégie data-driven ?
Dans le cadre d’une stratégie data-driven, le calcul distribué est un levier clé pour exploiter pleinement la valeur des données et optimiser la prise de décision. Plus une entreprise fonde sa stratégie sur la donnée, plus elle doit être en mesure de traiter rapidement des volumes importants d’informations pour en tirer des insights pertinents.
L’un des grands avantages de Spark réside dans sa capacité à traiter de très grandes volumétries de données en un temps réduit. Cela signifie que les entreprises ne sont plus limitées à des échantillons restreints, mais peuvent au contraire analyser l’ensemble de leurs données. Or, plus un échantillon est large, plus les indicateurs calculés sont fiables et représentatifs de la réalité. En finance, par exemple, pouvoir traiter toutes les transactions d’une journée plutôt qu’un sous-ensemble permet d’obtenir des modèles de risque plus précis.
Grâce à Spark Streaming, cette capacité d’analyse peut s’appliquer en temps réel, offrant ainsi la possibilité d’adapter une stratégie au fil de l’eau. Spark Streaming permet d'intégrer des données provenant de diverses sources en temps réel. Cela permet de construire des pipelines de traitement de données en continu, qui alimentent des applications d’analyse ou de prise de décision sans nécessiter une intervention humaine. Une entreprise peut par exemple ajuster ses campagnes marketing à la volée en fonction du comportement des utilisateurs sur son site web ou de l'engagement sur les réseaux sociaux. Plus concrètement, si une marque constate une montée en popularité de certains produits en temps réel, elle peut décider d’activer immédiatement des promotions ciblées ou ajuster l'affichage des publicités pour maximiser l'impact.
En parallèle, Spark apporte également une infrastructure fiable et résiliente. La tolérance aux pannes du calcul distribué garantit que même en cas de défaillance matérielle, les traitements critiques continuent sans interruption, un élément essentiel lorsqu’une entreprise s’appuie entièrement sur ses données pour prendre des décisions. Cela est possible grâce à plusieurs mécanismes internes de Spark, notamment la recalculabilité des RDD (Resilient Distributed Datasets) : si une partition est perdue, Spark peut la reconstruire à partir des transformations précédentes, sans avoir besoin de relancer tout le pipeline.
Enfin, cette approche permet aussi de mieux maîtriser les coûts. Le calcul distribué optimise l’allocation des ressources en utilisant une gestion dynamique de la charge de travail, ce qui permet aux entreprises de tirer le maximum de leurs infrastructures en limitant les coûts.
Spark est un levier mais pas une fin en soi
Pour conclure, avec l’essor du Big Data et la démocratisation des outils d’analyse, adopter une stratégie data-driven devient essentielle pour les entreprises car cela leur permet de prendre des décisions stratégiques de manière éclairée. Au-delà du défi technologique, c’est une stratégie qui repose sur des changements profonds, à tous les niveaux de l’entreprise, des processus de prise de décision. Nous avons vu que le calcul distribué, et notamment Spark, est un levier technologique pour la mise en place d’une telle stratégie. Attention cependant à ne pas tomber dans l’écueil de vouloir utiliser Spark systématiquement.
Premièrement, Spark excelle dans le traitement de volumes massifs de données distribués sur plusieurs nœuds. Cependant, l'utilisation de Spark n'est pas toujours justifiée. Dans certains contextes métiers, des traitements automatisés en Python ou SQL peuvent être plus simples, rapides et économiques à mettre en place. Spark est plus complexe à maîtriser et à optimiser, ainsi les ressources humaines qualifiées sont rares et coûteuses. Par exemple, pour automatiser le traitement de fichiers de taille modérée déposés sur un datalake à intervalles réguliers, pandas peut suffire amplement. De manière générale, si la taille d’un fichier est inférieure à la taille de la mémoire de la machine utilisée, alors Spark n’est souvent pas la solution la plus appropriée (la limite se situe généralement aux alentours de quelques Go).
Second point, le matériel informatique est en constante amélioration, on est donc capable de traiter des volumes de données de plus en plus importants sur un seul nœud. Cela peut remettre en question la nécessité de solutions distribuées comme Spark. Le postulat de la solution DuckDB, qui propose une approche différente en traitant les données directement sur le serveur, illustre cette tendance.
Ainsi, bien que Spark soit une solution robuste pour les gros volumes de données, il est essentiel d'évaluer chaque contexte spécifique pour déterminer si d'autres outils ou approches ne seraient pas plus appropriés.
Le sujet vous intéresse ? Nos experts vous répondent

Avec la création d’un pôle spécialisé en Data/IA, mc2i se positionne comme un partenaire de confiance en Data Transfo au service de la démocratisation de la donnée et d’un usage responsable.




