


10 ans de big data : prise de recul et perspectives

Une décennie s’est écoulée depuis la première édition du salon parisien du Big Data en mars 2012. Dix ans d’actualité effrénée durant lesquels la valse des effets de mode et buzzwords n’a jamais cessé : Hadoop, BI self-service, datalab, datalake, dataviz, calculs in-memory, … L’occasion d’une prise de recul, d’une synthèse rétrospective et d’un panorama des principales tendances à l’œuvre, le tout sans aucune prétention d’exhaustivité !
Poser le contexte grâce à l’analyse des buzzwords
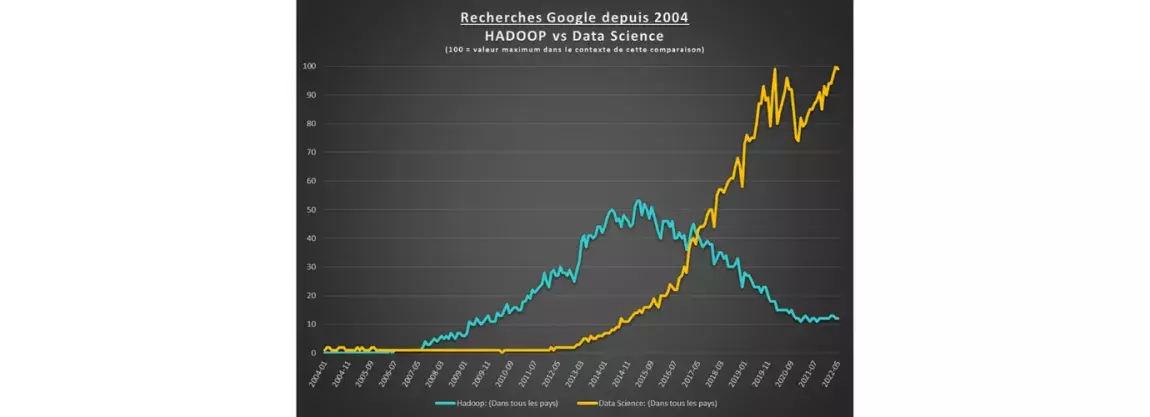
Comme en atteste une analyse rapide sous Google Trends (voir graphique plus bas), la science de la donnée a fortement attiré l’attention des internautes ces 5 dernières années, tandis qu’un terme phare de la première vague du big data tel que “Hadoop” a connu une décroissance marquée et régulière.
Une explication à ce phénomène pourrait résider dans l’effacement de la notion d’architecture distribuée - dont hadoop était un des fers de lance - par les offres « cloud » auxquelles les organisations recourent désormais massivement pour supporter leurs usages de la donnée.
Autre indice traduisant ce glissement vers les usages et la science de la donnée, l’incontournable salon “Big Data Paris” a été renommé “Big Data and AI” en 2021.
Pour autant, il serait réducteur de cantonner les tendances du monde de la donnée à quelques mots-clés ou à l’intitulé des grands événements rythmant le calendrier des professionnels du secteur. Qu’en est-il de la réalité de terrain, au sein des organisations productrices et utilisatrices de la donnée informatique ?
Intelligence artificielle : un essai difficile à transformer ?

C’est un fait corroboré par les initiatives constatées chez la plupart des grandes organisations : des cellules de R&D spécifiques se sont structurées chez les grands comptes sous forme de « Datalab » exploitant des « Datalakes », qu’ils soient dédiés à des fins de recherche pratique et théorique, d’usine logicielle ou encore de vitrine technologique.
Cependant, au-delà des lignes métier déjà utilisatrices d’algorithmes complexes (marketing, finance de marché, assurances, …), la valeur ajoutée de l’intelligence artificielle peine à se matérialiser au quotidien. Entre autres causes : le caractère disparate et la qualité variable des données source disponibles dans les applications d’entreprise, la difficulté à mesurer la quantité d’informations à valeur prédictive pouvant en être extraites et enfin le défi de l’explicabilité des algorithmes.
La démocratisation des plates-formes comme Dataiku permet certes facilement d’entraîner un algorithme et de produire des prédictions, mais l’effet « boîte noire » demeure. Car les compétences pointues nécessaires à la mesure objective de la qualité de l’algorithme conçu sont rares, tout en étant difficiles à évaluer dans les processus de recrutement. Or comment décider de l’industrialisation d’un algorithme sans en connaître ses limites ?
La révolution industrielle globale que devait entraîner la science de la donnée n’a dans les faits pas toujours eu lieu directement dans les DSI. Celle-ci semble aussi se dérouler silencieusement via l’intégration de l’IA dans les solutions des éditeurs et industriels spécialisés : reconnaissance d’image intégrée aux smartphones, traduction automatique, détection de fraudes…
Les apports de l’IA sont aussi à tempérer par rapport aux gains potentiels de productivité liés à la rationalisation ou au bon respect des processus métiers théoriquement en vigueur dans les organisations. Ou bien encore simplement par rapport au fléchage des investissements vers l’outil de production en place. Les nombreux secteurs en crise capacitaire aujourd’hui nous le rappellent de façon évidente.
Informatique décisionnelle : entre modernisation et conservatisme ?

Les outils de restitution ont continué leur modernisation, avec les solutions de visualisation qui ont vu se succéder Qliq, Tableau et désormais Power BI en tête des benchmarks. Microsoft a mis en œuvre sa capacité d’investissement pour amener son offre cloud et analytique au meilleur niveau, avec par exemple une percée remarquée de Power BI chez les clients institutionnels, tandis que SAP et IBM ont poursuivi une modernisation de leurs plates-formes historiques.
A noter également la tendance à l’utilisation de solutions de visualisation indépendantes des grands éditeurs historiques qu’elles soient open source (D3S, Plotly, Charts.js…) ou propriétaires (Datawrapper, Flourish, …). Ces graphiques, souvent dynamiques et animés, sont abondamment utilisés par les articles de presse en ligne et les sites spécialisés dans des domaines à dominante analytique comme l’épidémiologie, l’économie ou la démographie. Certaines solutions se positionnent d’ailleurs clairement sur le data-storytelling et l’infographie, à l’image de Toucan Toco.
En parallèle et sur certains cas d’usage, la BI « self-service » encouragée par les éditeurs se confronte à la complexité des données source et des indicateurs souhaités. On en revient alors parfois aux méthodes traditionnelles de spécification et d’homologation de traitements et de rapports labellisés.
Enfin, plus que jamais les DSI se sont tournées vers la migration des infrastructures dans le cloud, y compris les fonctions de stockage et d’analytique propres aux usages décisionnels (Amazon Redshift, Snowflake, …).
Gouvernance et urbanisation des données : des progrès inégaux

La théorie voudrait que toute donnée du SI soit cartographiée, modélisée, décrite et caractérisée via des métadonnées. L’émergence de réglementations supra-étatiques comme le RGPD ont certes poussé les organisations à structurer les processus de gestion du cycle de vie de la donnée, mais les exemples d’industrialisation réussie de la gestion des métadonnées au travers d’outils du marché semblent rares. La plupart du temps, celle-ci reste supportée par des fichiers bureautiques classiques.
Du point de vue des flux de données, on peut noter une forte volonté d’ « APIsation » des échanges, qui vise à standardiser les modes de sollicitation des systèmes via la conception et le déploiement d’API. Dans la même logique, les pipelines de données basés sur des solutions scalables et distribuées comme Apache Kafka viennent concurrencer les anciennes files JMS et autres transferts de fichiers plats par protocole sftp.
En soutien à cette tendance, les solutions d’ESB (Enterprise Service Bus) se transforment pour intégrer d’une part les nouvelles connectivités attendues par les clients, mais aussi les fonctionnalités d’administration et de surveillance des API. A ce titre, la solution MuleSoft de Salesforce occupe une place de choix sur le marché.
Enfin, l’urbanisation des flux passe de plus en plus par la définition de « data hubs » supportant un catalogue centralisé de données accessibles de façon normée par les applications clientes au travers de contrats d’échange formels, avec pour but de limiter les flux point à point entre applications et l’anarchie qui peut rapidement en résulter.
Et pour demain ?

Le secteur des places de marché centralisant et harmonisant les offres d’open-data ou de données propriétaires est encore balbutiant, avec seulement quelques acteurs réellement visibles, comme Dawex.
Mais il est vraisemblable que l’offre passera par une phase d’effervescence avant de se consolider autour de quelques grands acteurs…Et peut-être de tomber dans l’escarcelle des géants de la « tech » étant donnée leur expérience incomparable de plate-formistes.
Par ailleurs, dans le contexte d’inflation des coûts énergétiques, du réchauffement climatique et de la part croissante du numérique dans la consommation énergétique, le sujet de la frugalité numérique va devenir de plus en plus importante pour les DSI, qui devront adapter leur politique en conséquence.
Les pénuries ou le renchérissement de composants matériels pourraient aussi inciter à étendre la durée de vie des infrastructures et à optimiser l’exploitation des capacités de calcul et de stockage, deux ressources dont les systèmes analytiques sont particulièrement friands.
Nous pouvons aussi présumer que les promesses de l’informatique quantique appliquée aux bases de données ou à l’IA viendront régulièrement faire la une dans les salons et éditos avant que la moindre application pratique ne voie le jour…
Car en l’état, la maturité technologique des ordinateurs quantiques est encore très loin d’apporter un quelconque avantage par rapport aux ordinateurs classiques.
Il sera donc probablement préférable de conserver une distance critique vis-à-vis des effets d’annonce, surtout dans un contexte de concurrence entre Chine et USA sur le sujet.
Un avenir structuré autour des géants de la tech et de niches sectorielles ?

A la complexité des concepts mathématiques utilisés par les usages avancés de la donnée s’ajoutent la difficulté à mesurer la réelle valeur ajoutée de ces usages pour l'organisation, ainsi que l’impératif de maîtrise des infrastructures et middlewares sous-jacents…Nombre de sujets très consommateurs de ressources financières et humaines, qui tendent à détourner les organisations de leur cœur de métier.
Et comme il est impensable que chaque organisation se mue en acteur à la hauteur des GAFAM, il est possible que l’innovation effective vienne de l’enrichissement des offres packagées proposées par ces grands éditeurs, comme cela s’est passé pour les offres d’hébergement et d’infrastructures dématérialisées.
Mais le positionnement agnostique et transverse des géants de la tech offrira sans doute des niches pour les innovateurs faisant le pari de la symbiose entre algorithmes intelligents, processus métier traditionnels et parfois outillage matériel. Car jusqu’à maintenant, les solutions de gestion RH, de comptabilité, de supply chain ou encore d’imagerie médicale ne sont pas légion dans le catalogue des GAFAM.
Le sujet vous intéresse ? Nos experts vous répondent

Avec la création d’un pôle spécialisé en Data/IA, mc2i se positionne comme un partenaire de confiance en Data Transfo au service de la démocratisation de la donnée et d’un usage responsable.



