


Datalake & Datawarehouse : Substituables ou Complémentaires ?

La donnée est au cœur de nombreux enjeux: anticiper les besoins et la demande, optimiser son offre, optimiser sa logistique et son organisation ou encore analyser le comportement des consommateurs. Afin d’exploiter au mieux cette précieuse ressource, la mise en place d’outils ayant pour but de collecter, stocker et classer ces données s’est avérée cruciale.
L’objectif est de disposer en permanence des capacités nécessaires à leur traitement rapide. C’est dans cette optique qu’interviennent les deux outils que nous détaillerons dans cet article : datalake & datawarehouse.
Le terme datalake a été utilisé pour la première fois par James dixon en 2010 : au fil des années, de nombreuses définitions se sont succédées pour, aujourd’hui, aboutir à celle-ci : un datalake est un entrepôt centralisé qui contient des données sous leur format le plus brut et granulaire possible, qu’elles soient structurées, semi structurées ou non structurées provenant de différentes sources.
Le datawarehouse a été défini quant à lui une première fois dans les années 1970 par Bill Inmon. Depuis, les solutions de datawarehouse ont été désignées comme des entrepôts centralisés de données permettant de prendre des décisions mieux informées. Les données proviennent d'un large éventail de sources souvent non structurées et le deviennent une fois dans le datawarehouse après traitement.
Datalake ou Datawarehouse : Quelles différences ?
Comparaison et complémentarité
Au travers de ces deux définitions, on s’aperçoit que les deux outils ont une approche différente du type de données stockées, de l’usage qui en est fait et de l’objectif métier derrière. L’idée n’est donc pas de les opposer fondamentalement, mais plutôt de tirer profit de la complémentarité qu’offrent ces outils aux entreprises. Il devient donc de plus en plus courant d’utiliser les deux.
Pour bien comprendre l’utilité de chacun et leur complémentarité, il faut s’intéresser aux principales différences entre ces deux outils :
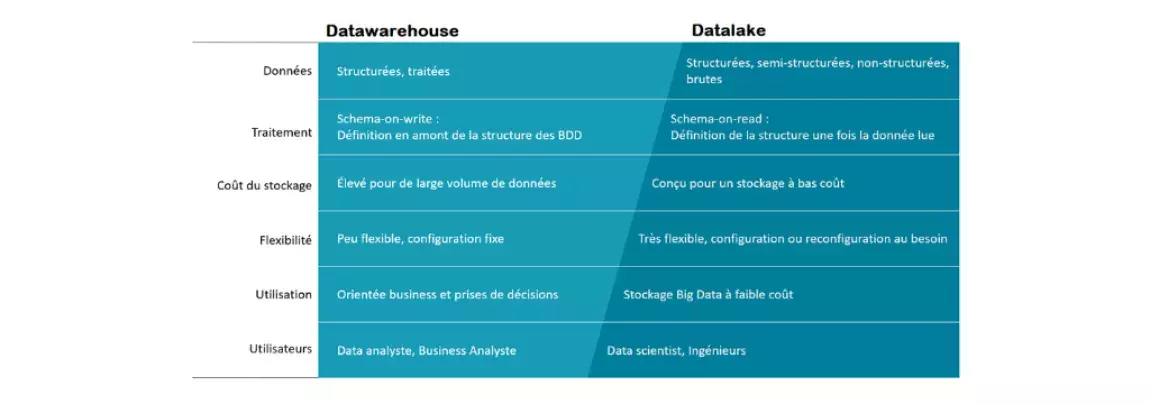
Le datalake n’est surtout pas à considérer comme une évolution d’un datawarehouse, les deux outils sont conçus et optimisés pour des usages différents. Le datalake peut intervenir en amont du datawarehouse, il va permettre à l’entreprise de regrouper l’intégralité des données à faible coût. Cependant, on ne connaît pas la qualité des données que l’on stocke dans un datalake, il est impératif avant tout traitement de gérer la qualité de la donnée : une tâche coûteuse en ressource, et particulièrement en temps. Ces données pourront ensuite être traitées, structurées et utilisées pour répondre aux différents besoins de l’entreprise. Un datalake sera donc pertinent, par exemple, pour les data scientist ou ingénieurs afin d’alimenter leur modèle avec le plus de données possibles.
A l’inverse, un datawarehouse offre une architecture et une discipline permettant de fournir des données régies et de bonne qualité. Cet outil est par conséquent orienté stratégie. Par exemple, la demande forte et permanente pour un ensemble d’indicateurs clés de performance (KPI), de reporting business ou reporting réglementaires exigent des données fiables et très contrôlées. Il est important de noter qu’un datawarehouse n’est pas qu’une base de données relationnelle, il est construit pour stocker des grandes quantités de données, permettant des requêtes rapides et complexes sur l’ensemble des données.
Risque à l'utilisation d'un datalake
Avant de mettre en place un datalake ou datawarehouse, il est important d’évaluer les risques potentiels. Un datawarehouse est conçu avec une architecture lourde, structurée, très peu flexible et bien définie en amont, ce qui permet de limiter les risques. La mise en place d’un datalake présente toutefois plus de risques.
Malgré les avantages procurés par un datalake comme la centralisation de l’information, il est facile de tomber dans les travers de cet outil. En effet, bien qu’il soit possible de stocker n’importe quel type de données sans limite de quantité, cela peut conduire à de nombreux problèmes. Le stockage intempestif de données en fait partie. Sans possibilité de catégoriser ou hiérarchiser l’information, le désordre peut rapidement prendre le dessus en enlevant la potentielle valeur des données. Ajouté à cela, les infrastructures stockant les datalake sont souvent très coûteuses et lourdes ce qui peut impliquer des problèmes de latence dans le traitement de l’information. Enfin, la confidentialité des données peut être mise à mal, les données pouvant fuiter plus facilement sur ce type d’infrastructure très ouverte.
Ainsi, le principal challenge n’est pas de créer un datalake, mais de tirer profit des opportunités qu’il représente et l’amélioration continue est donc indispensable pour faire de cette infrastructure une valeur forte.
Complémentarité des outils
Finalement, il faut retenir que ces deux outils ont été pensés pour répondre à des besoins métiers très différents. Il est possible d’utiliser les deux, et mettre en place des synergies, mais ils restent au final indépendants l’un de l’autre. C’est pour cela qu’il est important de bien définir son besoin pour choisir l’outil adéquat au préalable, la mise en place de tels outils représentant un investissement financier conséquent.
D’un autre côté, il ne faut pas perdre de vue qu’un datalake, encore plus qu’un datawarehouse, ne se met pas en place du jour au lendemain mais se construit peu à peu et a besoin d’évoluer constamment pour qu’il continue à un être un atout et non pas un obstacle.
Quentin Sauvignet - Erwan Manchot



