


Open Data : comment ouvrir vos bases de données ?

Le 07 octobre 2016, il y a un près d’un an et demi, la loi pour une république numérique a été adoptée. Parmi les mesures phares : la mise en ligne par défaut des données publiques – l’Open Data. Cette libéralisation s’inscrit dans une tendance de fond. Lancée depuis la fin des années 90 en France, l’objectif est de libérer l’accès aux données publiques, pour permettre plus de transparence et stimuler l’émergence d’actions citoyennes et d’innovation. Cette libéralisation a un coût non négligeable : 4 millions d’euros par an pour la maintenance du site data.gouv.fr par exemple. Mais les bénéfices de tels marchés sont également énormes. L’étude MEPSIR de 2006 prévoyait un marché européen de l’ordre de 30 milliards d’euros. Sans parler des avantages possibles en termes de civisme, d’écologie, de formation...
L’Open Data du secteur privé
Si cette libéralisation est légalement obligatoire pour le secteur public, qu’en est-il des entreprises privées ? Bien plus réticentes à donner accès à leurs données, celles-ci auraient pourtant elles aussi tout intérêt à le faire : innovation, audits, productivité, les avantages sont nombreux. Un tel projet ne peut néanmoins se mener sans une préparation et une réflexion en amont : quel plan d’action pour mettre en place une libéralisation de la donnée ?
Diffusion et gouvernance
Avant de lancer tout projet, il convient d’identifier le vecteur de diffusion qui sera utilisé ; il faudra ainsi tenter d’analyser et de comprendre le type de données dont on dispose ainsi que leurs particularités. Deux options peuvent être envisagées :
- Le premier mode de diffusion se fait sous la forme de fichier brut, en format standardisé (type csv, JSON, …) téléchargeable directement sur un portail : il s’agit du mode de diffusion le plus facile à mettre en place, mais également le plus difficile à maintenir. A noter qu’il est mal adapté aux gros volumes ou à des données évoluant rapidement.
- L’alternative est l’utilisation d’API : plus complexes à mettre en place, elles nécessitent également de structurer les données ; l’API joue le rôle de protocole de communication entre le serveur détenant les données et l’utilisateur final qui peut effectuer des requêtes dans un langage propre à l’API. Il est alors beaucoup plus facile de maîtriser les accès en lecture, voire dans certains cas en écriture.
Cette étude amont doit également être celle de la mise en place d’une gouvernance : diffuser des informations, même en interne, équivaut à prendre le risque de les retrouver en externe (malveillance, inattention, …). Il est impensable (et illégal avec le nouveau règlement RGPD), de libérer des données stratégiques ou personnelles. Les questions du format et de la qualité doivent également être abordées. Dans une optique de mise en place d’un datalake, les formats pourront être multipliés (texte, vidéo, …) sans traitement aucun. Mais dans le cadre d’une diffusion à des buts de reporting ou de pilotage, un pré-traitement d’harmonisation et de nettoyage sera nécessaire. Quoiqu’il en soit, le format doit être adapté à une utilisation industrialisée à grande échelle. Par exemple, la haute autorité pour la transparence diffuse ses données sous forme de pdf, les rendant pratiquement inexploitables.
La mise à disposition des données doit être progressive, afin de permettre à l’organisation de s’adapter aux changements de culture et de processus que cela entraine (but recherché in fine).
Le déroulé type d’un projet
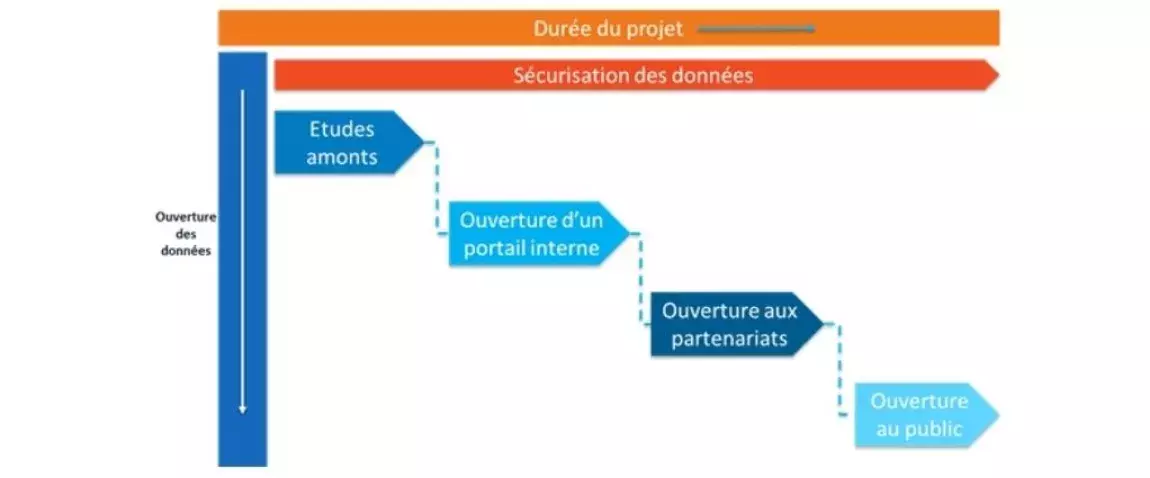
A la suite de cette étude amont, le projet en lui-même peut se découper en trois étapes.
Dans un premier temps, il convient de libérer ses données en interne, afin de commencer à propager une culture centrée sur l’utilisation et la qualité. C’est également l’occasion d’identifier les sources les plus utiles et de débuter des POC (Proof of concept). Encore une fois, la sécurité ne doit pas être négligée. Cette étape ne saurait constituer, en aucun cas, un test pour déterminer ce qui est stratégique et ce qui ne l’est pas. La gouvernance doit être mise en amont comme nous avons pu le voir précédemment.
Dans un deuxième temps, les données peuvent être laissées à des partenaires externes, dans le cadre de projets communs. Cette étape permet de s’assurer que les données sont compréhensibles et utilisables par des ‘extérieurs’ c’est-à-dire des acteurs ne venant pas du métier, ou même de l’entreprise. Ce sera alors le moment d’effectuer certains ajustements : Métadonnées, accessibilité des portails, ergonomie des API, performances, et ainsi de suite.
C’est seulement dans un troisième temps que les données pourront être libérées sous la forme d’Open Data au public.
Ces trois étapes imposent un raffinage progressif dans la compréhension des besoins et des data possédées en interne. Chacune d’elles doit avoir été individuellement menée à bien : l’objectif est d’avoir identifié les projets à fort ROI que l’on pourrait mener en interne avant de rendre les données publiques, mais également de raffiner la quantité mise à disposition. L’intégralité d’un projet d’ouverture doit donc se faire conjointement avec plusieurs entités de l’entreprise afin de s’assurer de n’avoir laissé passer aucune opportunité.
Voici un exemple de macro planning type d’un projet Open Data :
Pour conclure, mettre à disposition ses données peut être un véritable projet stratégique. Il s’agit d’ouvrir la possibilité de créer de nouveaux usages, de favoriser l’innovation. Mais, plus que tout, c’est l’occasion pour les entreprises de mettre en place une culture de la donnée. En formant ses salariés à l’importance de la qualité, à la manipulation de la donnée et à la prise de décision basée sur des faits, les bénéfices pour les entreprises peuvent être très importants. L’avantage compétitif obtenu par les géants d’internet, tels que les GAFA, est basé sur leur capacité à utiliser tout ce qu’ils collectent. C’est également aujourd’hui devenu possible pour des entreprises plus ‘traditionnelles’, à qui il manque principalement l’habitude et les processus. Pour de telles entreprises, la difficulté réside dans l’initiation de ces processus en motivant les équipes. Un projet type ‘Open Data’ peut alors constituer une bonne occasion de les mettre à l’épreuve.
Le sujet vous intéresse ? Nos experts vous répondent

Avec la création d’un pôle spécialisé en Data/IA, mc2i se positionne comme un partenaire de confiance en Data Transfo au service de la démocratisation de la donnée et d’un usage responsable.


